SystemsSystems & ML2026
Distributed Neural Network
Multi-layer perceptron built from scratch in C++17, accelerated with SIMD and distributed across workers over TCP.
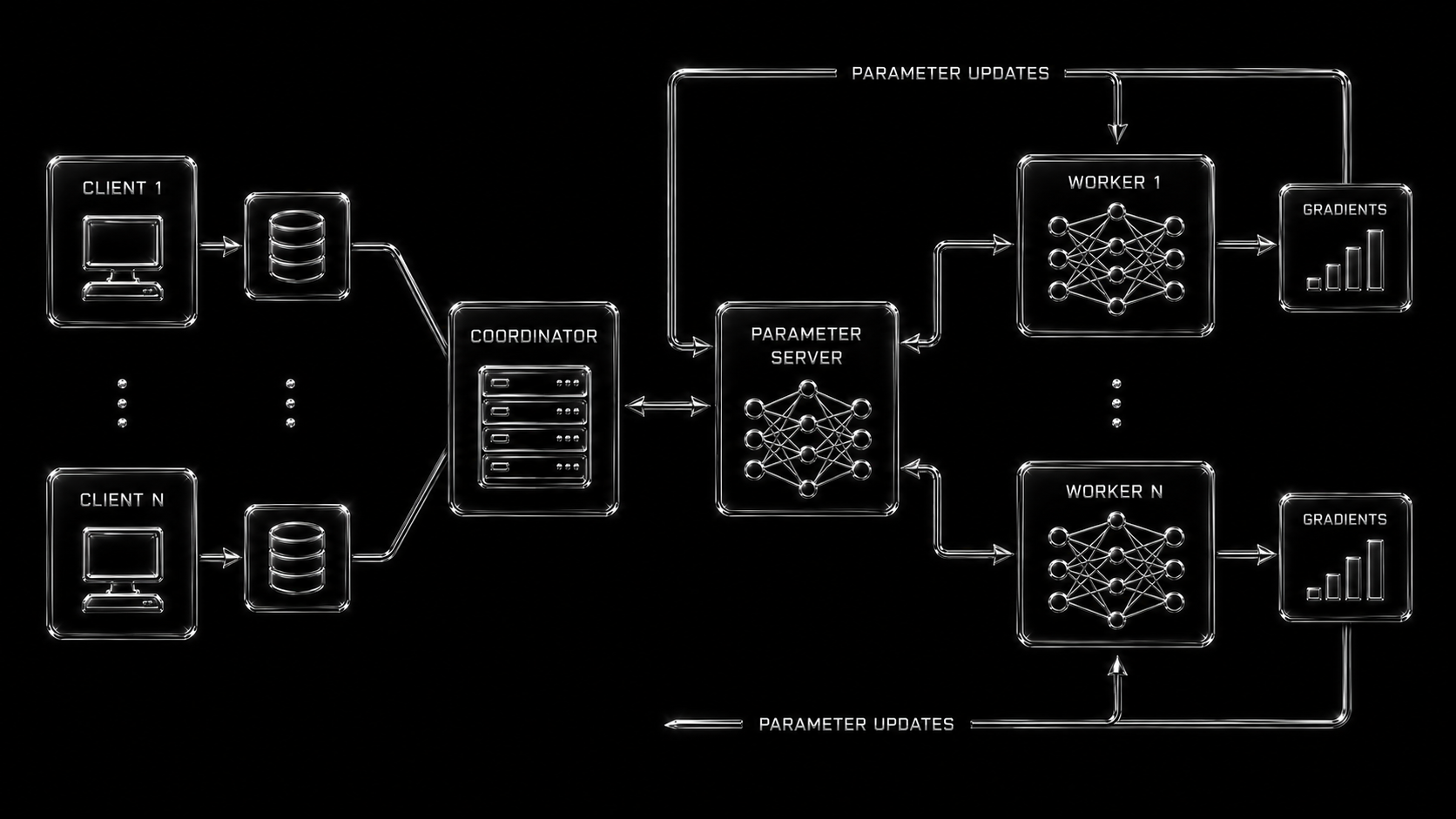
Product Surface
Technical Specification
Year2026
Highlights
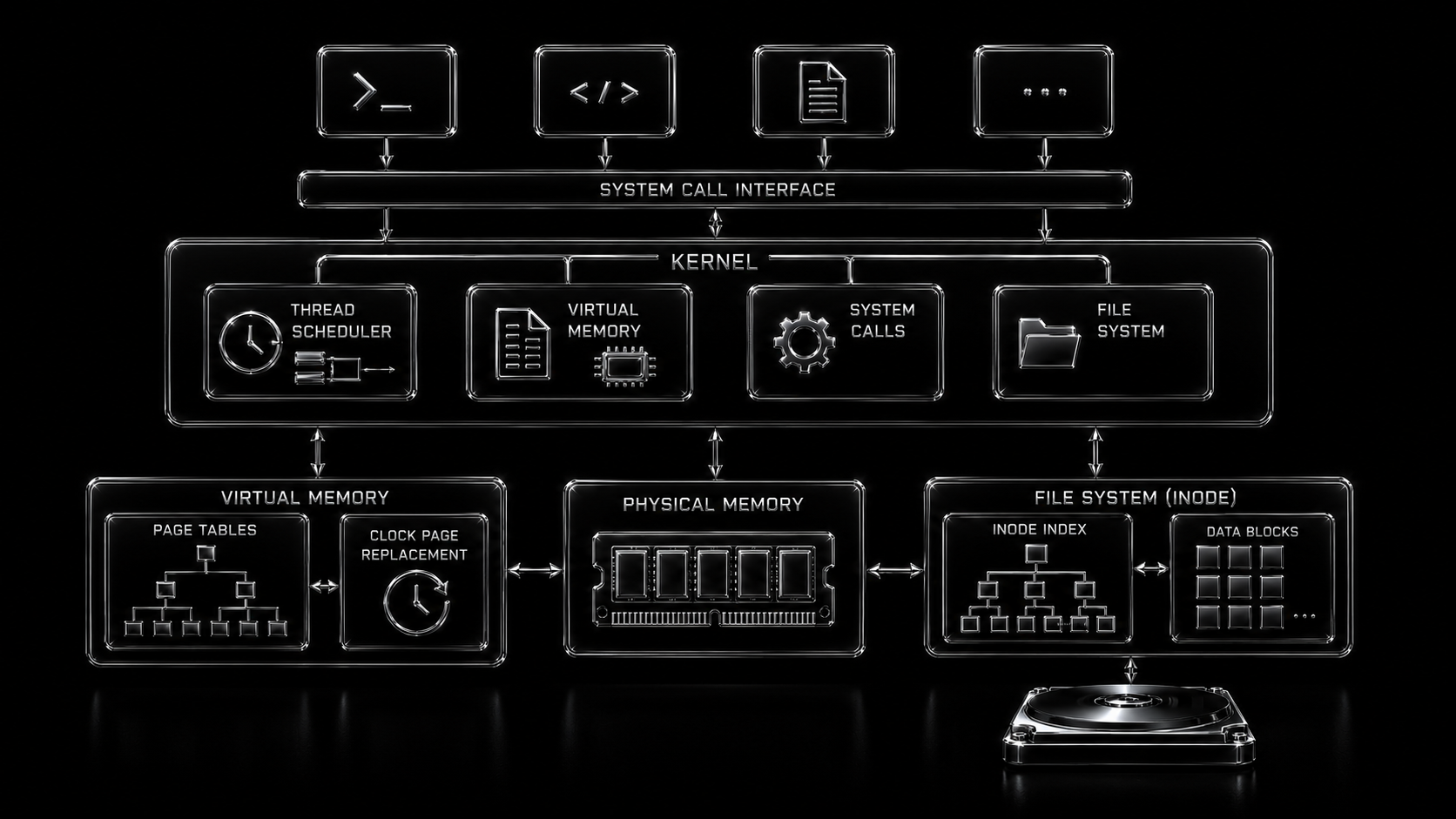
Next
Multi-layer perceptron built from scratch in C++17, accelerated with SIMD and distributed across workers over TCP.
Product Surface
Technical Specification
Highlights
Next